











































Abstract
Modern Text-to-Image (T2I) Diffusion models have revolutionized image editing by enabling the generation of high-quality photorealistic images. While the de facto method for performing edits with T2I models is through text instructions, this approach is non-trivial due to the complex many-to-many mapping between natural language and images. In this work, we address exemplar-based image editing – the task of transferring an edit from an exemplar pair to a content image(s). We propose ReEdit, a modular and efficient end-to-end framework that captures edits in both text and image modalities while ensuring the fidelity of the edited image. We validate the effectiveness of ReEdit through extensive comparisons with state-of-the-art baselines and sensitivity analyses of key design choices. Our results demonstrate that ReEdit consistently outperforms contemporary approaches both qualitatively and quantitatively.
Method
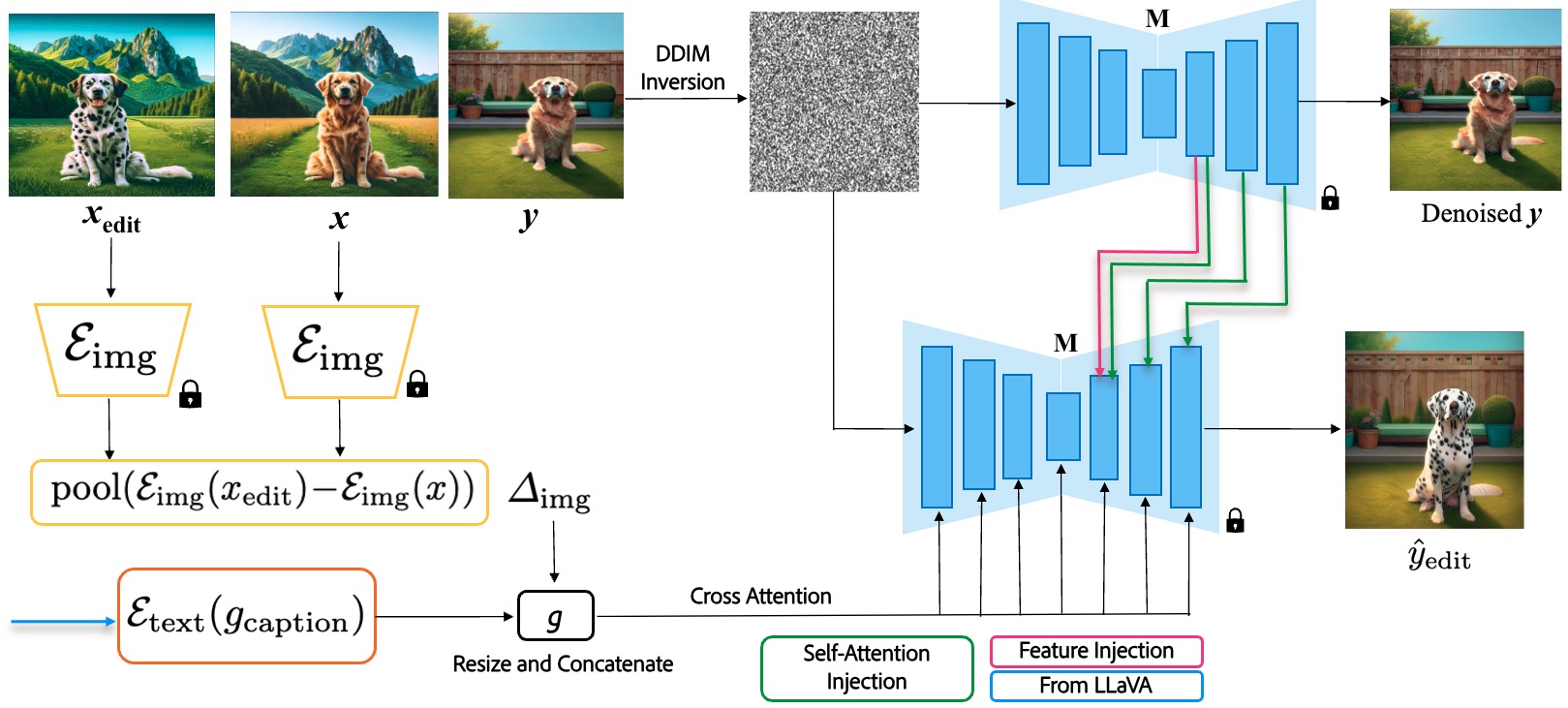
Our method involves a sophisticated process of exemplar-based image editing using diffusion models. The approach begins with extracting image embeddings from both the original image \(x\) and the edited exemplar \(x_{\text{edit}}\) using the encoder \(\mathcal{E}_{\text{img}}\). The difference between these embeddings is pooled to form \(\Delta_{\text{img}}\), capturing the nuanced details of the edit. Simultaneously, text guidance is incorporated through \(\mathcal{E}_{\text{text}}(g_{\text{caption}})\), providing additional context for the edit. These components are combined into a guidance vector \(g\), which is used to condition the diffusion model \(M\).
The process involves DDIM inversion to map the target image \(y\) into a latent space, followed by denoising to maintain the structural integrity of the original image. The model employs cross attention, self-attention injection, and feature injection to ensure precise and contextually relevant edits. This method allows for high-quality image transformations that respect the original content while applying the desired changes, as demonstrated in the final output \(\hat{y}_{\text{edit}}\).
Dataset Creation
The dataset used for evaluation consists of a diverse range of edits, carefully curated to ensure a comprehensive representation of various editing techniques. The table below summarizes the types of edits included in the dataset:
| Type of Edit | Number of Examples |
|---|---|
| Global Style Transfer | 428 |
| Background Change | 212 |
| Localized Style Transfer | 290 |
| Object Replacement | 366 |
| Motion Edit | 14 |
| Object Insertion | 164 |
| Total | 1474 |
Summary and statistics of the types of edits in the evaluation dataset. Special care was taken to ensure diversity of edit categories.
Effect of Varying Hyperparameter Lambda














Depiction of the effect of edit weight λ on the edited image. Higher values correspond to higher influence from the desired edit.

Example of ReEdit output.
BibTeX
@InProceedings{Srivastava_2025_WACV,
author = {Srivastava, Ashutosh and Menta, Tarun Ram and Java, Abhinav and Jadhav, Avadhoot Gorakh and Singh, Silky and Jandial, Surgan and Krishnamurthy, Balaji},
title = {ReEdit: Multimodal Exemplar-Based Image Editing},
booktitle = {Proceedings of the Winter Conference on Applications of Computer Vision (WACV)},
month = {February},
year = {2025},
pages = {929-939}
}